During Sunday’s Access Code class, Alex shared a cool fact with me about Wikipedia that I hadn’t heard before: clicking the first link in any Wikipedia article, then continuing to click the first link in each subsequent article, will eventually lead you to http://en.wikipedia.org/wiki/Philosophy.
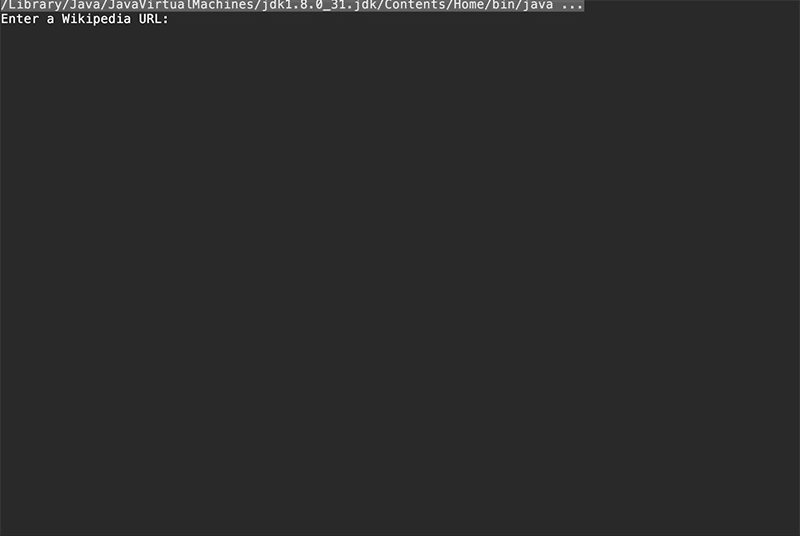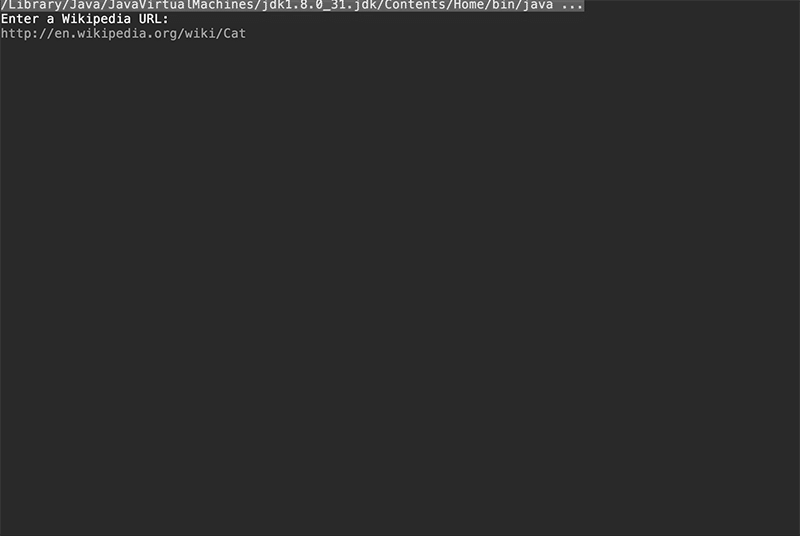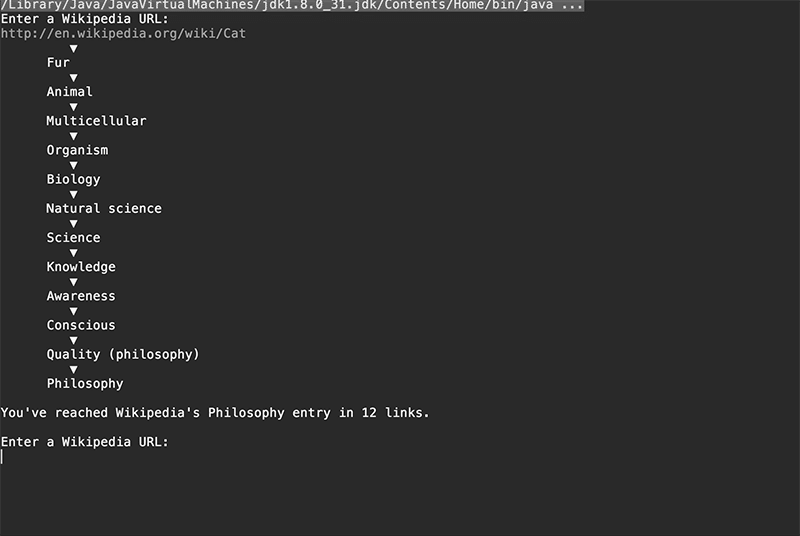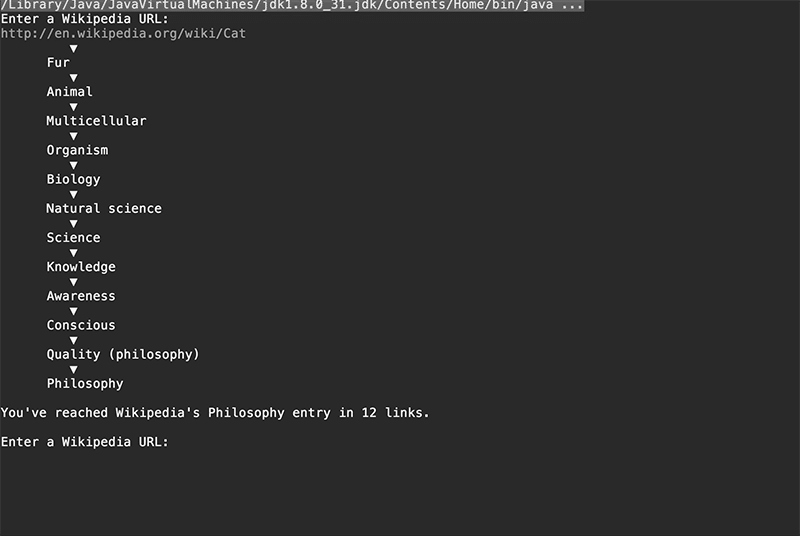
This seemed too odd to be true, so my pair-programming partner Elvis and I opened a browser and immediately set about testing it. Our first article: cat. Lo and behold, just 12 clicks later we arrived at the Philosophy article!
How does this work? As the Wikipedia article on “Wikipedia: Getting to Philosophy” explains, the Wikipedia Manual of Style recommends that each article should start by defining the topic of the article. This creates a likelihood that the first link will lead to a broader subject, eventually leading to the broadest of all subjects, philosophy. It’s cited that as of May 2011, 94.52% of articles lead to Philosophy. The median number of clicks is just 23.
Since Sunday’s class was all about getting comfortable with HTTP and Java’s URL class, I decided to exercise some of my new knowledge by building a program that could tell me how many clicks any Wikipedia article is from Philosophy.
Using the same API for HTTP.java that we used in class, I created a new project with a Main.java and HTTP.java.
In Main.java, below my main() method, I created a new method called findPhilosophy(), which takes a String argument (a Wikipedia URL) and returns a String (the next Wikipedia URL):
public static String findPhilosophy(String article) throws IOException {
// resets counter and breaks loop when philosophy article is reached
if (article.equalsIgnoreCase("http://en.wikipedia.org/wiki/philosophy")) {
int total = linkCounter;
linkCounter = 0;
return "\nYou've reached Wikipedia's Philosophy entry in " + total + " links.\n";
// ... or if more than 100 links have been tried
} else if (linkCounter > 100) {
linkCounter = 0;
return "\nToo far away...\n";
// builds next string URL, prints title to the console, increments counter
} else {
String nextLink = grabNextLink(article);
printTitle(nextLink);
linkCounter++;
return findPhilosophy(nextLink);
}
}
The first thing the method above does is check if the URL it’s being passed is the URL of the Philosophy article. If so, it resets the counter and breaks, returning a String with the total number of links counted.
If not, it next checks how many links have been counted so far. If linkCounter > 100, it resets the counter and breaks, returning a String that reports “Too far away…”. This ensures that the program won’t run forever if it can’t find Philosophy or gets stuck in a weird loop.
The next section is the real ‘meat and potatoes’. Here, findPhilosophy():
- Converts the (String) URL to a (URL) URL.
- Goes to the URL and grabs whatever HTML it finds, storing it as an object of the class Document.
- Parses the HTML for links, selecting the first non-parenthetical link in the actual content.
- Builds that link up into a (String) URL, called nextLink.
- Adds 1 to the link counter.
- Calls on itself, by returning findPhilosophy(nextLink).
This process is repeated until the first check returns true, meaning that http://en.wikipedia.org/wiki/Philosophy is reached, or until the value of linkCounter exceeds 100.
The hardest part of this project, by far, was grabbing the right 'first link’ from the HTML. The rules specify that the link has to be non-parenthesized, non-italicized, not external, not the current page, and not a 'red link’ (non-existent entry).
I struggled through writing a few methods from scratch to grab the right link, but found that inconsistencies in styling across articles meant my methods were unreliable. Alex suggested trying jsoup, which is a Java library designed for extracting data from HTML. I hadn’t used any third-party Java libraries yet, but after I got past the initial challenge of downloading and importing the library, jsoup made grabbing the right link super easy!
Jsoup lets you find elements using CSS selector syntax. I used jsoup to grab all of the <a> elements within <p> elements (the links within the actual article content). I then selected the first one that led to /wiki/ content and wasn’t language-related (e.g Greek, Latin, Old English).
public static boolean isFirstRealLink(String link) {
// filters out most language and pronunciation and non-wiki links
return (link.contains("wiki") && !link.contains("Greek") && !link.contains("Latin") && !link.contains("wiktionary"));
}
This method could be improved upon to cover more of the cases laid out in the rules, but for now the simple version has been working fine.
Here’s what the program looks like when you run it:
I was learning to code on my own, in my spare time, for more than half a year before starting Access Code. I mostly wrote 'toy’ programs: fun little puzzles that drew animations or solved math problems.
I’m super excited that I got this exercise to work because in a way, this is my first 'real’ program: it’s my first program that uses HTTP to send and receive information over the internet, and it’s my first program that interacts with the world outside of my computer and brings back interesting information that would otherwise be difficult to find. Yay!
I’m so happy that over the next few months, we’re just going to keep learning more about how to make our code interact with the 'real world’ to do amazing things.
Here’s the code, all together (you can also look at the project on my GitHub):
package nyc.c4q.ramonaharrison;
/**
* Access Code 2.1
* Ramona Harrison
* Main.java
*
* Takes a Wikipedia URL as input and follows the first link in each subsequent article,
* summing the link count until the wikipedia.org/wiki/philosophy page is reached
*
*/
import java.io.IOException;
import java.net.URL;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Main {
static int linkCounter = 0;
public static void main(String[] args) throws IOException {
Scanner sc = new Scanner(System.in);
while(true) {
System.out.println("Enter a Wikipedia URL:");
String input = sc.next();
if (!isValidUrl(input)) {
System.out.println("Please format input as a valid URL, for example: http://en.wikipedia.org/wiki/Nocturnality\n");
continue;
}
System.out.println(findPhilosophy(input));
}
}
public static String findPhilosophy(String article) throws IOException {
// resets counter and breaks loop when philosophy article is reached
if (article.equalsIgnoreCase("http://en.wikipedia.org/wiki/philosophy")) {
int total = linkCounter;
linkCounter = 0;
return "\nYou've reached Wikipedia's Philosophy entry in " + total + " links.\n";
// ... or if more than 100 links have been tried
} else if (linkCounter > 100) {
linkCounter = 0;
return "\nToo far away...\n";
// builds next string URL, prints title to the console, increments counter
} else {
String nextLink = grabNextLink(article);
printTitle(nextLink);
linkCounter++;
return findPhilosophy(nextLink);
}
}
public static String grabNextLink(String article) throws IOException {
String nextLink = "";
URL url = HTTP.stringToURL(article); // builds URL from string
Document doc = Jsoup.parse(url, 100000); // parses wiki page, times out after 100 seconds
Elements links = doc.select("p > a"); // selects only links within <p> tags
for (int i = 0; i < links.size(); i++) { // chooses the first suitable link
if (isFirstRealLink(links.get(i).toString())) {
nextLink = links.get(i).toString();
break;
}
}
return "http://en.wikipedia.org" + nextLink.substring(9, nextLink.indexOf("\"", 10));
}
public static void printTitle(String article) {
// formats titles for printing to the console
System.out.println(" ▼\n " + article.substring(29).replace("_", " "));
}
public static boolean isValidUrl(String input) {
// filters out improperly formatted URLs
return input.startsWith("http://en.wikipedia.org/wiki/");
}
public static boolean isFirstRealLink(String link) {
// filters out most language and pronunciation and non-wiki links
return (link.contains("wiki") && !link.contains("Greek") && !link.contains("Latin") && !link.contains("wiktionary"));
}
}